▶ pwd
- 현재 경로 보기
- usage : pwd
[root@localhost root]# pwd
/root
[root@localhost bin]# pwd
/bin
▶ cd
- 디렉토리 이동 //cd = change directory
- usage : cd [인자값]
. -> 현재 디렉토리
.. -> 상위 디렉토리
[root@localhost root]# cd /var
[root@localhost var]#
[root@localhost root]# cd ..
[root@localhost /]#
▶ ls
- 파일 내역 출력 //"ls -al"을 가장 많이 쓴다. 모든 파일을 자세히 출력 가능
- usage : ls [ option ] [ directory / file ]
▶ cp //copy
- 파일, 디렉토리 복사 //상위 폴더로 복사하기 - # cp sample.txt ../
- usage : cp [ option ] [ source ] [ target ]
▶ mv //move
- 파일, 디렉토리 이동
- usage : mv [ option ] [ source ] [ target ]
▶ mkdir //make directory
- 디렉토리 생성
- usage : mkdir [ option ] [ directory name ]
▶ rmdir //remove directory
- 디렉토리 삭제
- usage : rmdir [ option ] [ directory name ]
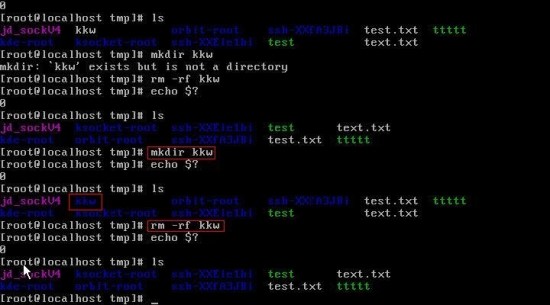
추가적인 옵션 없이 그냥 # mkdir kkw 입력으로 폴더를 생성할 수 있다. 그리고 왠만하면 습관적으로 # echo $?를 써주는 것이 좋다고 한다. # echo $?이라는 것은 앞의 작업이 잘 수행되었는가를 확인하는 명령어다. 0이 출력되면 정상적으로 잘 수행 되었다는 말이고, 만약 0 이외의 수가 출력 된다면 무언가 문제가 생겼다는 것을 의미한다. 참고로 Linux에서는 숫자 2는 오류를 의미한다. # ls를 입력해서 파일 내역을 출력해 볼 수있다. 그 다음 kkw 폴더를 삭제하기 위해서는 위에서 설명한 rmdir이 있다. 하지만 실무에서는 삭제하려는 것이 있다면 거의 rm -rf * 를 많이 쓴다. 습관화 되면 오히려 편하게 쓰일 것이다.
▶ rm //remove
- 파일, 디렉토리 삭제
- usage : rm [ option ] [ directory / file ] //그냥 지우는 건 무조건 rm -rf로 삭제!
▶ cat //remove
- 텍스트 파일 내용 출력
- usage : cat [ file name ]
- 인자값 > : 파일 내용 덮어 씌우기
- 인자값 >> : 기존 파일 내용 추가
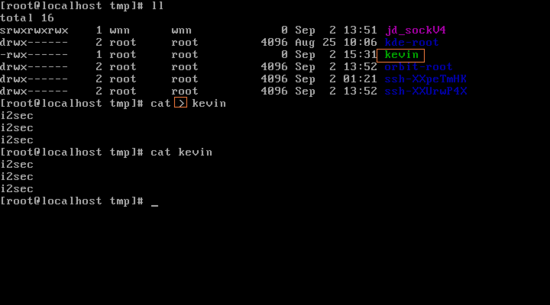
cat > kevin redirection 명령으로 "i2sec" 3개를 입력하고 ctrl+D(저장 후 바꾸어 나오기) 입력한다. 다시 cat kevin으로 파일 내용을 출력 해보면 저장한 대로 "i2sec"이 저장되어 있다.
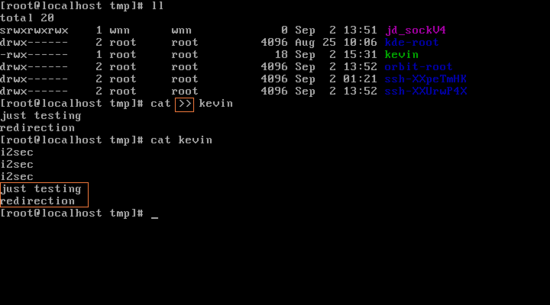
> redirection 같은 경우에는 그냥 보내는거다. 초기화를 하면서 쓰는 것이 > redirection이고, 반면에 >> redirection은 기존에 것은 그대로 두고 append 한다는 의미를 가지고 있다. 기존의 "i2sec" 아래에 just testing, redirection이 추가된 것을 볼 수 있다.
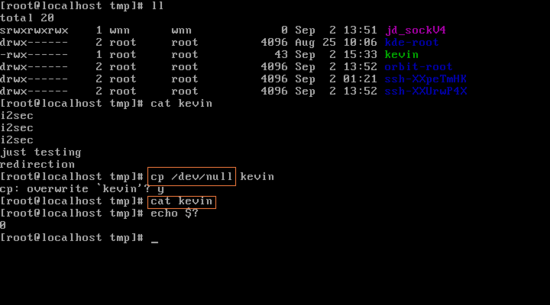
이번에는 redirection을 사용하지 않는 상태에서 특정 파일의 내용을 싹 지워보겠다. cp /dev/null을 파일명 앞에 넣어주면 된다. /dev/null에서 null은 한마디로 값이 없다는 뜻이다. kevin 파일에 그것을 cp == 복사한다는 것이다. 결국 내용이 텅 빈 kevin파일을 cat명령으로 출력해 보면 아무 것도 없다
리눅스 명령어(Linux Command)(2)
▶ touch //보안에서의 touch명령은 '시간 조작'으로 활용
- 파일 생성 및 시간 정보 변경
- usage : touch [ file name ]
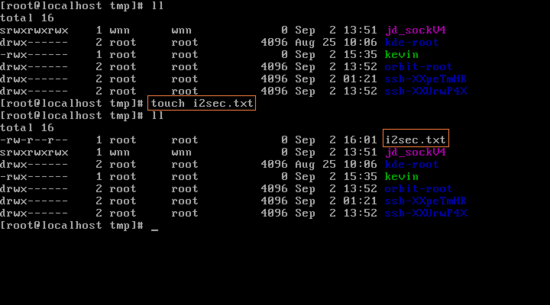
touch명령을 통해서 i2sec.txt 파일을 만들어 봤다. tmp directory을 출력해 보면 i2sec.txt파일이 생성된 것을 볼 수 있다. 참고로 몇 분 뒤에 똑같이 touch i2sec.txt를 해주면 접근 시간이 바뀌어 있을 것이다. touch명령은 말 그대로 어떠한 파일을 만지는 것이다. 옆에 보이면 시간은 가장 최근에, 최종적으로 접근한 시간을 의미한다.
▶ head
- 파일 내용 중 처음부터 10줄 출력
- usage : head [ file name ]
▶ tail
- 파일 내용 중 마지막부터 10 줄 출력
- usage : tail [ file name ]
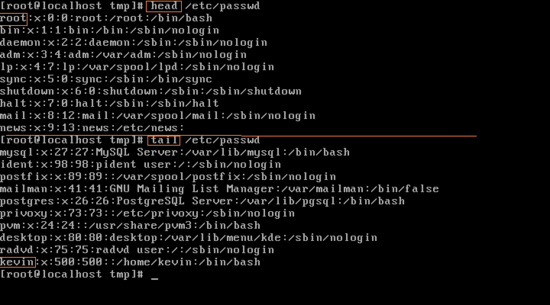
/etc/passwd에는 사용자 인증이 필요한 계정 정보들이 담겨 있다. 그대로 명령을 치면 꽤 길게 나오고 page가 넘어갈 것이다. 이럴 때 head나 tail이 잘 활용되고, 특히 실무에서는 head보다는 tail을 자주 쓴다. 가장 최근에 무슨 일이 있었는지 빠르게 볼 수 있기 때문이다. 일단 head를 /etc/passwd 앞에 붙이면 가장 top부터 10줄을 출력해준다. 당연히 root가 최고 권한의 계정이기 때문에 top에 위치해 있을 것이다. 옆에 'x'는 password를 가리키는 것인데, /etc/passwd는 아무나 열람이 가능하기 때문에 여기에 이렇게
많은 계정들의 password가 있을 수 가 없다. password는 따로 /etc/shadow에 저장되어 있다. 그 외 옆에 나열된 번호들은 뒤에서 다시 살펴볼 것이다. tail을 보면 맨 아래에 kevin이라는 계정이 있다. 가장 최근에 생성한 계정이 되겠다.
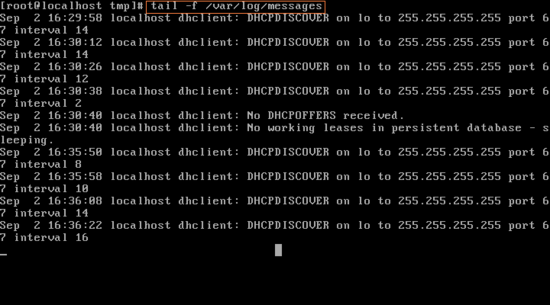
tail은 이런 면에서도 활용 될 수 있다. tail -f /var/log/messages명령으로 1번 콘솔(현재 root계정 login)에서 root의 접근 log를 실시간으로 monitoring 할 수 있다. 명령을 실행 시키면 아래로 로그가 뜰 것이다.
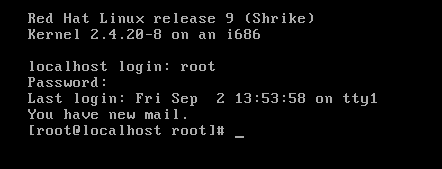
콘솔1에서 실시간 monitoring을 켜 놓고 콘솔 2에서 root로 login을 해보자. 다시 콘솔1로 돌아와 보면 접근 log가 뜰 것이다.
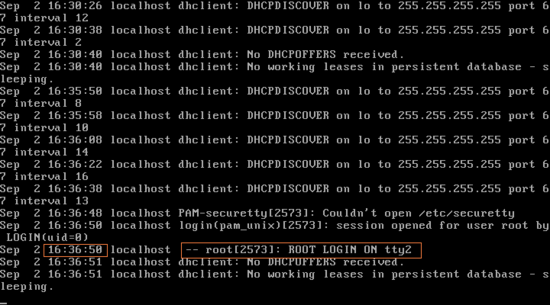
16:36:50에 root가 tty2에 login 했다.
▶ more
- 파일 내용 화면단위로 출력 //spacebar == 한 page 씩 출력, enter == 한 line 씩 출력
- usage : more [ file name ]
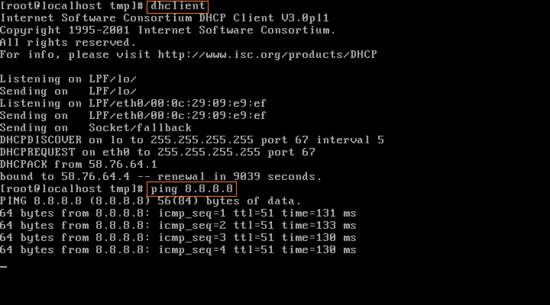
리눅스 명령어(Linux Command)(3) ▶ rdate - 타임서버 시간 조회 및 시스템 시간 변경 - usage : rdate [ option ] [ time server ] - 주요 타임서버(time.bora.net, ntp.ewha.net) //rdate -p time.bora.net : 타임서버 시간 조회(정확한 시간) //rdate -s time.bora.net : 타임서버 시간 시스템 동기화 //server를 운영할 때는 시간이 가장 중요하다
타임서버 시간을 조회하려면 일단 dhclient로 인터넷을 켜줘야 한다. dhclient 는 DHCP 를 이용해서 network설정을 자동으로 하는 프로그램이다. 이 후 정상적으로 작동되는지 ping test를 해본다. ping 8.8.8.8 명령을 했는데, 여기서 8.8.8.8은 google에서 운영하는 dns server이다. 이런 식으로 잘 돌아간 후에 타임서버 시간을 조회한다.
▶ file - 파일 종류 확인 - usage : file [ option ] [ file name ]
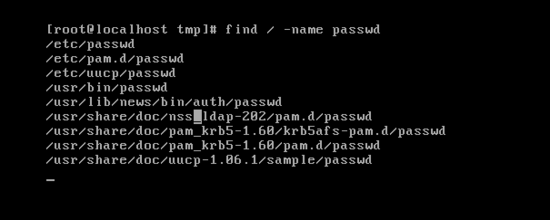
▶ find - 파일 찾기 - usage : find < 경로 > -name < file name >
예를 들어 root directory 아래에 passwd라는 이름으로 된 파일을 찾고 싶을 때 이런식으로 사용하면 가능하다.
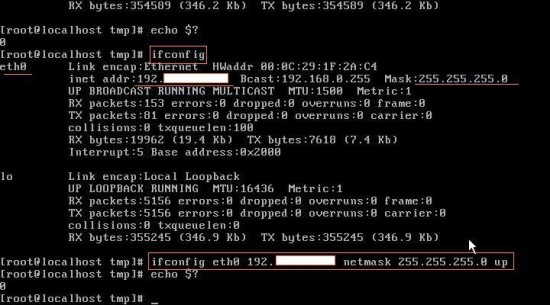
▶ ifconfig - network IP 설정 - usage : ifconfig [ network interface ] [ IP ] [ netmask ] [ up / down ] //ex) network interface == eth0
자신의 IP주소와 netmask를 수동으로 설정 해줄 수 있다. ifconfig [ network interface ] [ IP ] [ netmask ] [ up / down ] 이러한 양식으로 손쉽게 변경 가능하다. netmask 뒤에 붙는 up과 down의 차이는 살리고 죽인다는 명령이다.
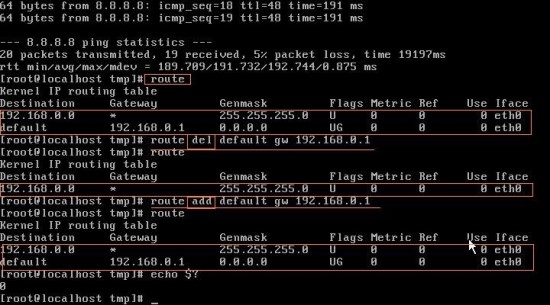
▶ route - gateway 설정 - usage : route [ add / del ] [ IP / NET ] //static IP : 정적 할당(수동) //DHCP IP : 자동 할당(자동)
route로는 gateway를 del과 add를 통해서 죽이고 다시 살릴 수 있다. route del default gw 192.168.0.1 명령으로 default를 지워준다. 다시 똑같이 del 부분을 add로 바꿔서 실행시켜주면 다시 살아난다. echo $?를 습관적으로 실행 시켜 주면서 오류가 발생하지는 않았는지, 이전 작업이 잘 진행 되었는지를 꼭 확인한다.
▶ shutdown - 시스템 종료 - usage : shutdown [ option ] [ time ] "messages" //ex) shutdown -h now == 지금 당장 종료 시키기
▶ pipe( | ) - 앞 프로그램의 결과를 뒤 프로그램의 입력 값으로 전달해주는 역할 - 다른 명령 조합 //ex) ls -al /usr/bin | more //ex) ls /usr/bin | less
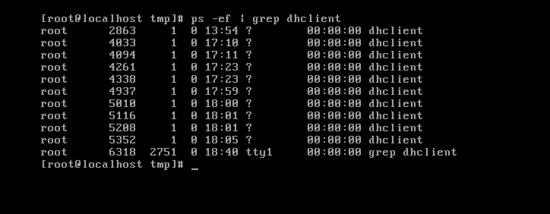
▶ filter(grep) - 표준 입력으로부터 자료를 읽어 간단한 처리 후 표준출력으로 보내는 프로그램 //ex) ps -ef | grep dhclient
ps -ef명령은 process를 열람 해라는 명령이다. 간단하게 말해서 ps -ef명령은 windows에서 ctrl+alt+del를 눌리면 나오면 작업관리자와 동일하다고 생각하면 된다. 아무튼 여기에 grep dhclient를 pipe로 묶은 상태에서 enter를 치는 순간 memory에 적재시킨다. dhclient는 당연히 출력되고 grep dhclient역시 출력된다. grep dhclient역시 process 되기 때문이다.
▶ 표준 입출력과 리다이렉션 - 표준출력 redirection 표준출력장치(모니터)의 방향을 파일로 전환 사용법 : >, >>
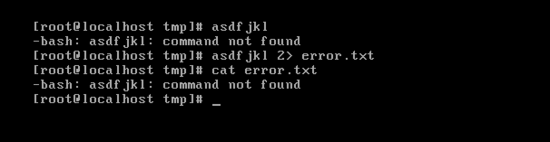
- 표준오류 redirection 사용법 : 2>, 2>> //리눅스에서 숫자 '2'는 error을 가리킨다. //ex) asdfjkl 2> error.txt -> 오류 미 발생시 파일 생성 안됨
'asdfjkl'라는 오류를 error.txt로 redirection 시키는 것이다. cat명령으로 error.txt 파일의 내용을 출력시켜 보면 asdfjkl라는 command를 찾을 수 없다고 나오게 된다.
|
'리눅스 > Tip' 카테고리의 다른 글
| GDB 사용 디버깅 작업 (0) | 2010.11.25 |
|---|